58 Schmidhuber Papers in Pure NumPy with Claude Code
58 Jürgen Schmidhuber paper stubs implemented in pure numpy via the same SPEC-driven agent-team workflow, with the build internals now grounded in raw session data
We did it again. 58 of Jürgen Schmidhuber’s experimental papers from 1989 to 2025 reimplemented in pure numpy via the same SPEC-driven agent-team workflow used a week earlier on Hinton’s catalog. The lineage is different and the algorithmic constraints are harder, but the machinery survived without modification.
schmidhuber-problems is the result. 12 supervised waves, 12 wave PRs and a meta PR merged in one batch, plus a later token-math fix. 32 reproduce paper claims, 25 are partial or qualitative reproductions with the gap documented, 1 is an honest non-replication shipped with mathematical analysis. 41 wall hours end to end, ~21 of those active human attention. The rest of the receipts are at the Build internals book, a structured drill-down of the session prompt-by-prompt and wave-by-wave.
This post is the sequel to the Hinton-problems post. The first post made the methodological case from one case study. This one reports what changed on the second run, with the cost summed from JSONLs instead of from memory and the human-in-the-loop ratio measured against the orchestrator’s full prompt log.
Why Schmidhuber
The trigger came from Yaroslav on 2026-05-05:
“@yad3k people are suggesting Schmidhuber, I created similar set of stubs here … could you fire off your agent swarm when you have quota? The thing that benefited me most from the previous experiment were 1. BUILD_NOTES.md 2. Experiment visualizations (to quickly verify that it worked) 3. workbook with runtime+implementationtime+(worked yes/no?) stats”
The three things Yaroslav liked from Hinton became the three deliverables for Schmidhuber: BUILD_NOTES, GIF visualizations, workbook stats.
The next message a day later was the green light: “Could you just do fire off whatever you did for Hinton for this one, no extra modification is needed.” That sentence is the methodological claim under test. A workflow that depends on its specific origin won’t transfer to a new domain without rework, and the second run is where you find out which one this is.
The two catalogs cover different territory. Hinton’s lineage leans representational, with small benchmarks where hidden-unit inspection is the payoff (Encoder-4-2-4, family trees, shifter, Forward-Forward MNIST). Schmidhuber’s lineage leans algorithmic. Long-time-lag indexing: flip-flop 1990, chunker 1992, adding-problem 1996, temporal-order 1997. Key-value binding: fast-weights 1992 and linear Transformers 2021, same outer-product math 29 years apart. Universal search: Levin 1995, OOPS 2004. Controller-plus-model loops in tiny stochastic environments: pole-balance 1990, World Models 2018.
The thesis being tested
Yaroslav put the framing in the Hinton issue thread and we lifted it almost verbatim into the Schmidhuber README:
“The field has standardized on backprop by the end of the ’80s, and Hinton gives a sample of problems that were used at the time. In the last 20 years, we have transitioned to GPUs, and the math has changed considerably. Instead of being bottlenecked by arithmetic, the shrinking of transistors means that arithmetic is essentially free, and all of the work comes from data movement. Backprop is inefficient in terms of ‘commute to compute ratio’ because it requires fetching all of the activations for each gradient add.”
That’s the research goal. Build a clean list of small reproducible learning problems, instrument them with a data-movement metric, look for solvers that beat backprop on that axis. The catalogs in v1 are the baseline list. v2 is the ByteDMD instrumentation Yaroslav asked for in issue #17. v3 is the search across the instrumented baselines.
The Schmidhuber catalog matters here because the 58 stubs include the candidate non-backprop primitives that v3 will eventually compare against: local rules, evolutionary methods, fast-weights, Levin search, predictability minimization. Reference implementations have to exist before anyone can measure their energy cost.
Four families, four GIFs
One stub per family, training dynamics from the actual runs. Click any GIF to open its stub README on GitHub. The README has the paper citation, the hyperparameters, the deviations from the original, and the open questions.
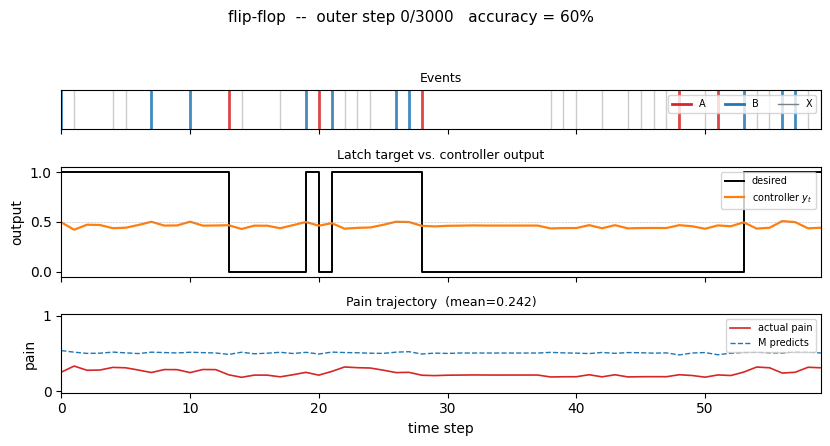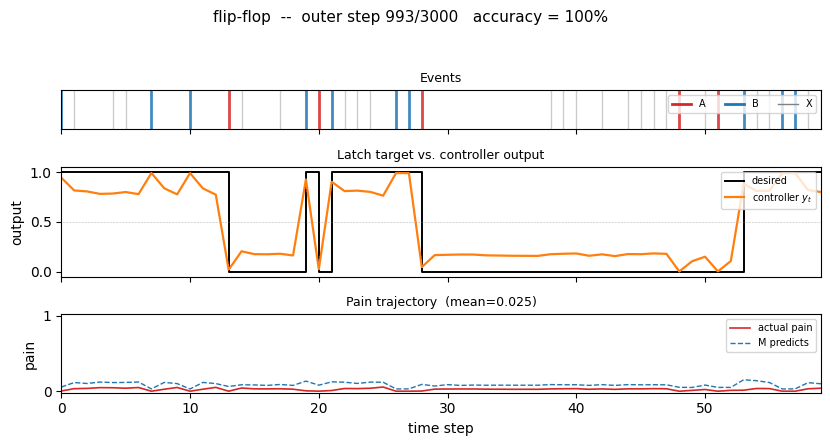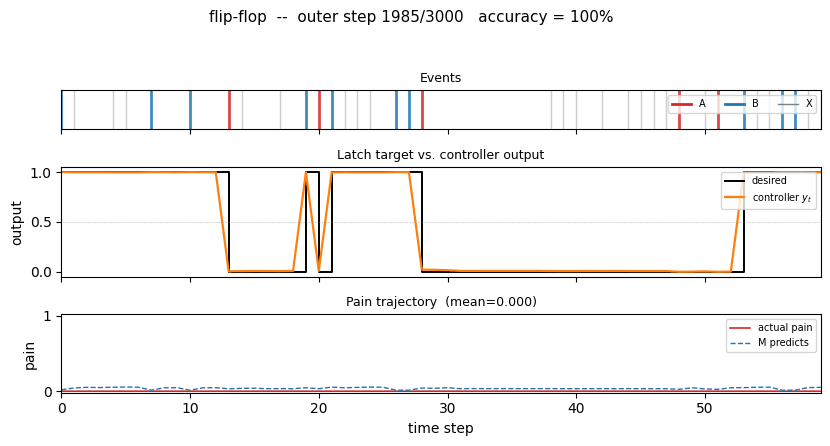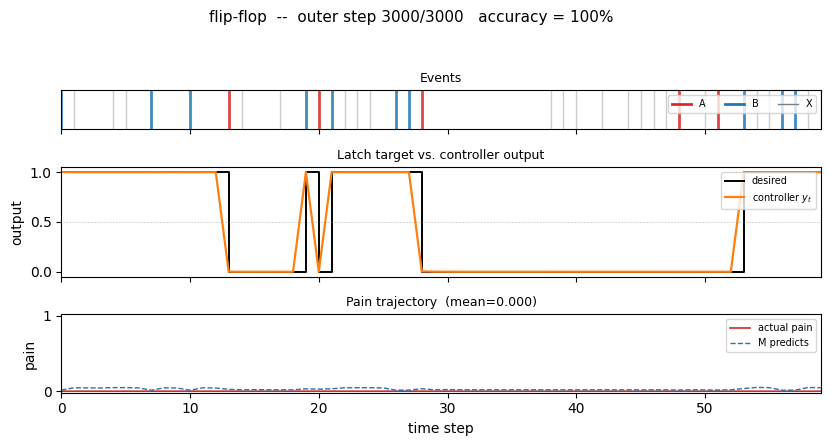
flip-flop (Schmidhuber 1990) — long-time-lag indexing. A controller has to latch event B until event A resets it, across unbounded delays of irrelevant Xs. The 1990 setup that Hochreiter later formalized as the vanishing-gradient barrier.
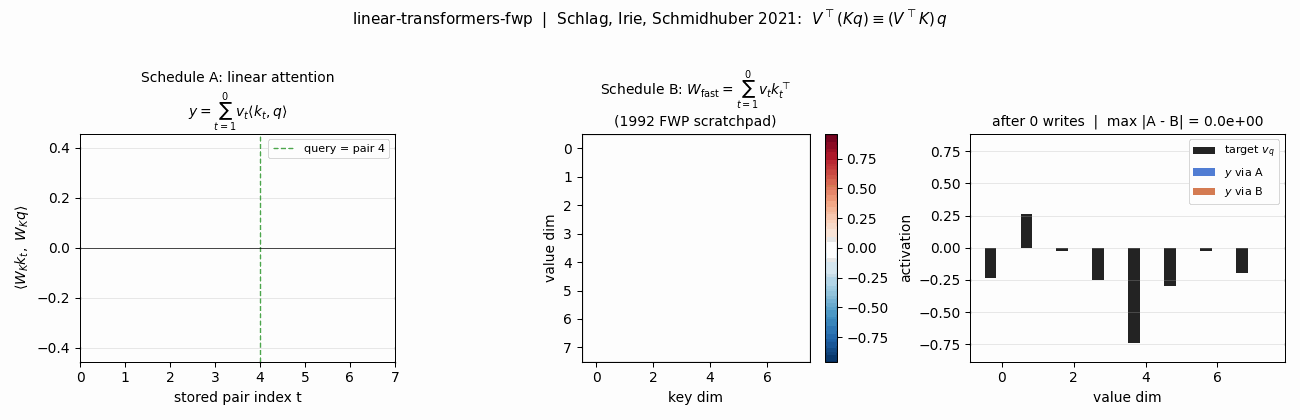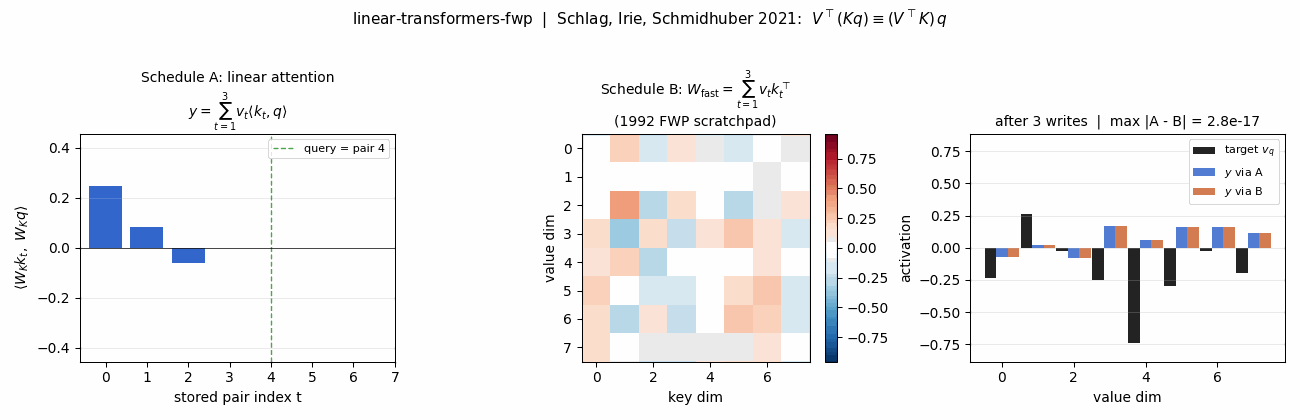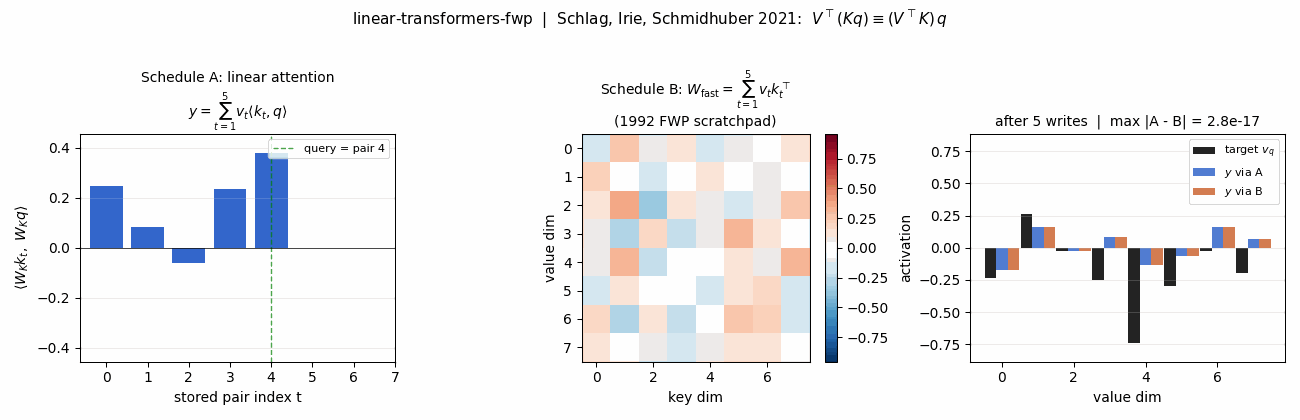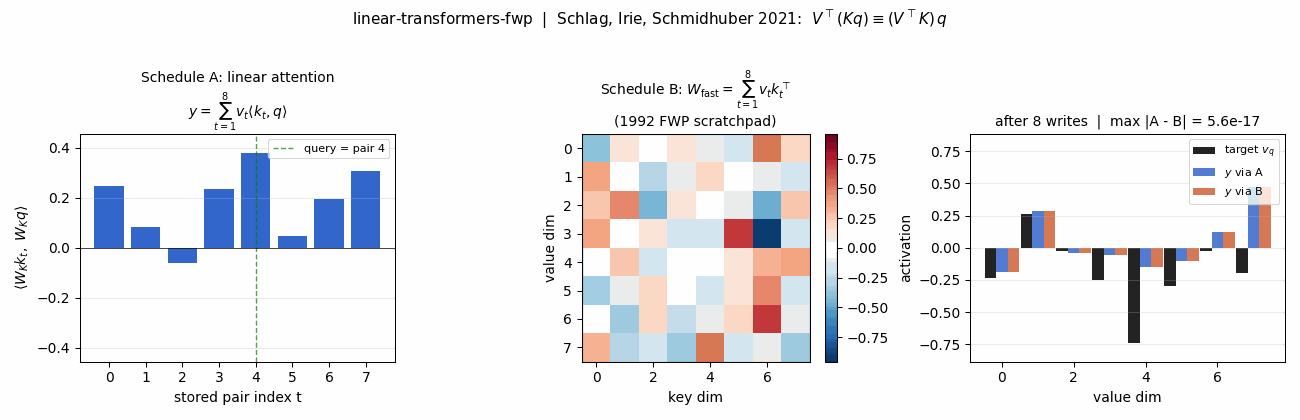
linear-transformers-fwp (Schlag, Irie, Schmidhuber 2021) — key-value binding. Unnormalized linear self-attention and the 1992 fast-weight programmer compute the same outer-product expression. The stub verifies the equivalence to 2.22e-16.
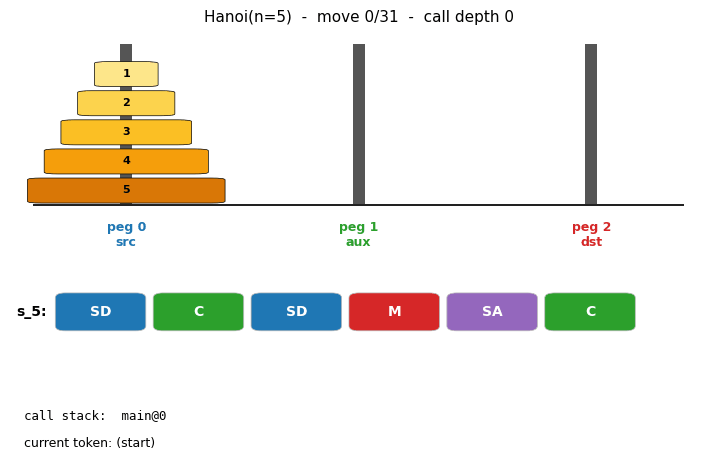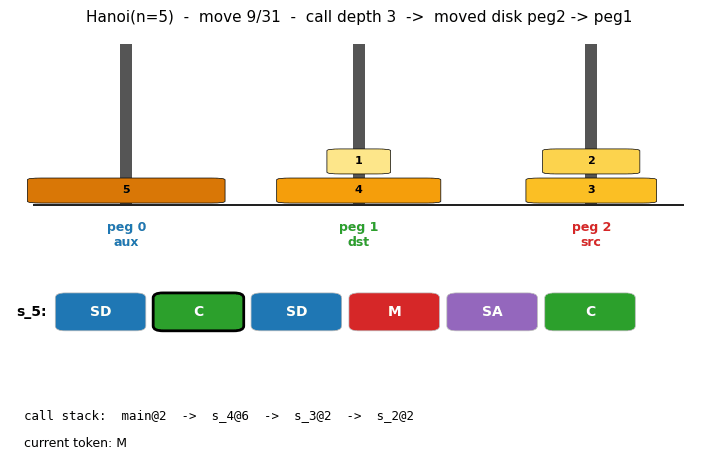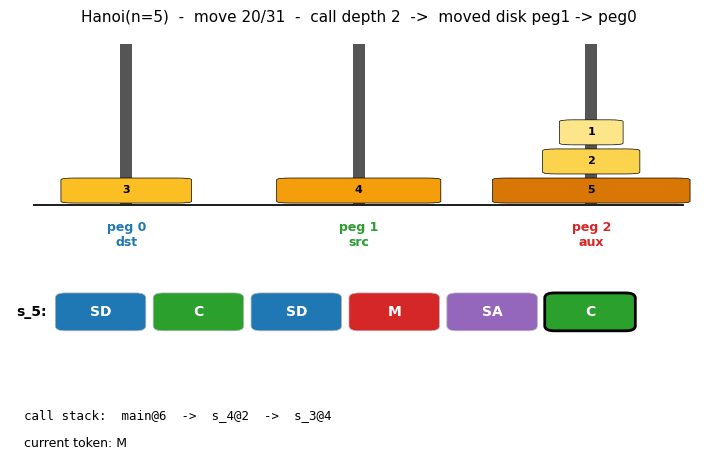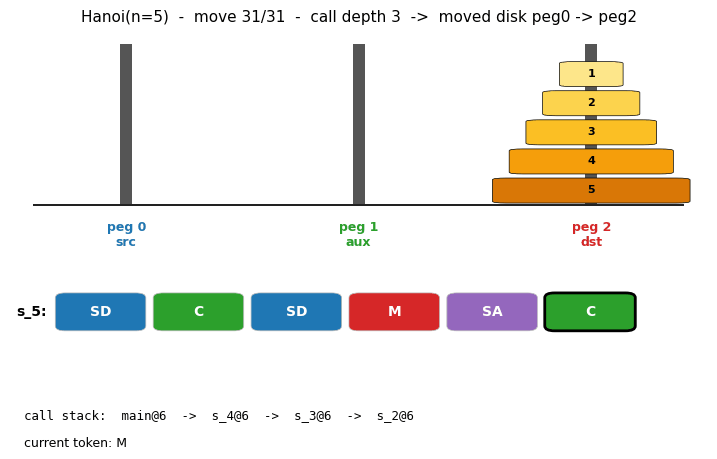
oops-towers-of-hanoi (Schmidhuber 2004) — universal search. Optimal Ordered Problem Solver discovers the recursive Hanoi solution via Levin search ordered by program length, reusing subroutines found for smaller n.

world-models-vizdoom-dream (Ha & Schmidhuber 2018) — controller-plus-model loop. Controller C trains entirely inside the dream of a learned recurrent world model M, then transfers zero-shot to the real env. v1.5 numpy substitute for the VizDoom install.
All 58 stubs have their own GIF and viz/ folder; the VISUAL_TOUR.md walks through them in order.
The SPEC, second iteration
Same shape as hinton-problems issue #1. A single GitHub issue every PR links back to. Eight required README sections plus an acceptance checklist. The domain-specific rules are what differ between the two runs.
Three Schmidhuber-specific additions were codified in the issue body before wave 0:
Algorithmic faithfulness over optimizer convenience. Long-time-lag stubs use the paper’s recurrent architecture. Evolutionary stubs use the paper’s evolutionary optimizer. Levin and OOPS keep universal search. No backprop shortcuts. The point of reproducing a 1992 fast-weights paper is to have a 1992 fast-weights implementation, not a backprop approximation that hits the same accuracy.
Architecture-deviation rule. If the paper’s exact architecture cannot converge under numpy-only constraints on a laptop, the stub runs a sweep of at least 30 seeds at the original architecture, documents the failure mode, and proposes a justified alternative. The deviation is recorded in the README’s §Deviations section so that no substitution happens without an explicit note.
RL-stub rule. Numpy mini-environments only. No gym, no gymnasium. The pole-balance stubs ship with the Barto-Sutton equations of motion in numpy. The POMDP-flag-maze stub ships with a numpy gridworld. The original simulators (CarRacing, VizDoom, TORCS, TIMIT, IAM, ISBI) are tracked as v1.5 follow-ups so v1 does not block on environment installs.
These three rules are domain-specific addenda. The core SPEC (required files, eight sections, acceptance checklist, reproducibility constraints) is identical to Hinton.
How the loop ran
The orchestrator created a single persistent team via TeamCreate and dispatched 58 parallel Agent calls into isolated worktrees, one per stub. Workers committed locally, reported back via SendMessage, awaited shutdown. After each wave, one Explore audit agent ran read-only across the wave’s stubs before the wave PR opened.
Per-wave sequence (the loop that ran 12 times):
Full per-wave timeline with first-dispatch and audit-dispatch UTC timestamps for each of the 12 waves: orchestration map.
The audit step is what caught the orphan problem.py files in waves 6 and 7. It runs read-only after the builders are done at ~3-8% overhead per wave. The audit for wave 0 was probably unnecessary on a single-stub wave; the rest justified their cost via the catches they made. Per-stub annotated worker prompt template at worker prompt anatomy, open questions about audit cost at what worked, what didn’t.
The execution model is parallel-within, sequential-across. All workers in a wave run concurrently; the audit gates the next wave. Wave 1 as an example:
The 12 waves
| Wave | Family | Stubs |
|---|---|---|
| 0 | sanity | nbb-xor |
| 1 | search | rs-two-sequence, rs-parity, rs-tomita, levin-count-inputs, levin-add-positions, oops-towers-of-hanoi |
| 2 | local-rules | nbb-moving-light, flip-flop, pole-balance-non-markov, pole-balance-markov-vac, saccadic-target-detection |
| 3 | rl-hidden-state | curiosity-three-regions, subgoal-obstacle-avoidance, pomdp-flag-maze, ssa-bias-transfer-mazes, hq-learning-pomdp |
| 4 | history-fastweights | chunker-very-deep-1200, chunker-22-symbol, self-referential-weight-matrix, fast-weights-unknown-delay, fast-weights-key-value |
| 5 | predictability | predictability-min-binary-factors, predictable-stereo, semilinear-pm-image-patches, lococode-ica |
| 6 | lstm-1 | embedded-reber, two-sequence-noise, multiplication-problem, adding-problem, noise-free-long-lag, temporal-order-3bit |
| 7 | lstm-2 | blues-improvisation, temporal-order-4bit, continual-embedded-reber, anbn-anbncn, timing-counting-spikes |
| 8 | evolutionary | double-pole-no-velocity, pipe-symbolic-regression, evolino-sines-mackey-glass, pipe-6-bit-parity |
| 9 | deep-mlps | highway-networks, mcdnn-image-bench, mnist-deep-mlp, compete-to-compute |
| 10 | modern | neural-em-shapes, relational-nem-bouncing-balls, linear-transformers-fwp, upside-down-rl, neural-data-router |
| 11 | v1.5 heavyweight | timit-blstm-ctc, world-models-carracing, em-segmentation-isbi, torcs-vision-evolution, clockwork-rnn, iam-handwriting, world-models-vizdoom-dream, lstm-search-space-odyssey |
Wave 0 was the sanity check, waves 1-10 the v1 catalog, and wave 11 the v1.5 heavyweight set bundled into the same run (TIMIT, IAM, ISBI, CarRacing, VizDoom, TORCS as numpy synthetic substitutes). All 13 PRs (the 12 wave PRs plus the meta PR) merged in a 90-second burst at 2026-05-08 15
–15 UTC. The per-wave drill-down is at /build-internals/waves/.Eight direction-changing prompts out of forty
Earlier drafts said “two course-correction prompts mid-run”. The count after walking the orchestrator’s JSONL and classifying every prompt against the build state at the moment it landed is eight, about one in five of my 40 typed prompts across ~21 active hours.
| UTC | Prompt (verbatim, Yad-typed) | What changed |
|---|---|---|
| 2026-05-06 23 | Pasted the SPEC link, the hinton-problems precedent, and Yaroslav’s Schmidhuber-papers suggestion. | Triggered the build. TeamCreate + wave-0 dispatch within 16 minutes. |
| 2026-05-07 00 | ”alright shall we do clean up and dispathc multiple agents to finish the rest of the waves?” | Wave-1 trigger. First parallel-dispatch wave. |
| 2026-05-07 01 | ”why are u doing a branch per impl, should it be per waves?? why the branch spam. THIS IS WRONG PRACTICE COURSE CORRECT!” | Wave 1 → wave 2 protocol pivot. PR #2 closed, reissued as PR #5 on wave/0-sanity. From wave 2 onward per-stub branches stay LOCAL ONLY. |
| 2026-05-07 02 | ”I need you to not rely on me anymore until you finish it all, basically, do wave into 1 per, audit, post to pr then trigger next wave” | Autonomous mode engaged. Eight subsequent waves ran without further intervention. |
| 2026-05-08 13 | ”BUT FIRST FIRST FINISH THESE THINGS REMAINING” | Wave 11 (v1.5) trigger. Prioritized finishing the catalog before site/docs. |
| 2026-05-08 15 | ”why are there teams reaminign thouhg?” | Caught the not-yet-shutdown teammate processes. Triggered team cleanup. |
| 2026-05-08 15 | ”have we verified thse things to be truely done or left over?” | Surfaced the unmerged-PRs gap. The 90-second batch-merge of all 13 PRs followed minutes later. |
| 2026-05-08 16 | (Redacted — frustrated venting about agent commit-author identity.) | Triggered the git filter-branch rewrite, 74 commits → Yad Konrad. |
The classification is at human in the loop; the verbatim quotes including the non-pivot prompts are at pivot moments.
The human in the loop is a local-minima escape
Cosmin Negruseri put a name on the pattern weeks before the build:
“I have the feeling I was useful by pinging some wave of agents to do diagnostics and that got the solution out of a local minima.” (2026-05-14)
Sung Jae Bae sharpened it the morning after Mark Saroufim’s MLSys keynote referenced this work:
“Seems to enter the local minima fairly quickly so adding some skills to creatively explore different directions.” (2026-05-21)
The data lines up with that. The autonomous loop did not self-detect the branch-spam problem at wave 1. The lead’s audit subagent didn’t either, because the audits checked stub quality rather than workflow correctness. My 01
prompt was the first time anything in the system named the pattern. The 15 prompt had the same shape: the loop had drifted past unmerged PRs and the lead hadn’t noticed.The remaining 32 of my 40 prompts split roughly into ~10 status checks, ~5 approval gates, and ~17 small clarifications or follow-up work after wave 11 (counts per human in the loop). The autonomous loop carried those without direction.
One honest non-replication with a math bound
The Wiering and Schmidhuber 1997 HQ-learning result on a 29-cell maze: both HQ and flat Q solve the training problem at roughly 100%, both fail at 0% on greedy evaluation. The paper’s headline gap between HQ and flat does not reproduce on the smaller maze.
Acknowledged in the wave-3 audit summary at 03:35:
“Implementation faithful, honest about the gap with mathematical analysis (γ^Δt · HV ≤ R_goal bound).”
The bound says: if the per-step discount factor γ raised to the option duration Δt times the highest hidden-state value HV is less than the goal reward, then no policy under hidden-state Q can prefer the goal-reaching option, regardless of training. The maze in the stub is small enough that the discount eats the goal reward before any policy can recover. The paper’s 62-cell maze is queued as a v1.5 follow-up.
This is what the SPEC’s “honest about deviations” clause looks like in practice. Where a stub doesn’t reproduce, the contribution is the analysis of why it doesn’t.
What the run cost
The aggregate from the JSONL session logs across all 74 sessions is $3,879 at Opus 4.x public pricing and 1.126 billion tokens.
Yaroslav asked after the Hinton post: “btw, how many tokens did it use?” My first answer of 750k was the orchestrator’s context-window meter that I read off the Claude Code TUI in the moment, which is the lead session’s current context fill and not cumulative spend, and which doesn’t include any of the 58 worker sessions. PR #20 corrected the number from the JSONL session logs.
Two pools combine to 77.5% of the bill: cache_read (41%) and cache_write_1h (36%). Output is third at 20.5%. Raw input tokens are negligible because the system and tool prompts were almost always cached.
The breakdown:
| Pool | Tokens | % of tokens | $/M | % of bill |
|---|---|---|---|---|
cache_read | 1,064 M | 94.5% | $1.50 | 41.2% |
cache_write_1h | 47 M | 4.2% | $30.00 | 36.3% |
output | 11 M | 0.9% | $75.00 | 20.5% |
cache_write_5m | 4 M | 0.4% | $18.75 | 2.0% |
input | 0.2 M | 0.0% | $15.00 | 0.1% |
The non-obvious finding is that cache_write_1h was 36% of the bill on 4% of the tokens. Every cache invalidation costs $30/M, twice the raw input rate. Most token-accounting tools don’t surface this because they show input and output but not cache-write-by-pool. For a long-running orchestration session, the 1-hour cache writes are where the money goes before output volume.
Workers cost more than the orchestrator: 67% of the bill on 58 sessions vs 33% on 1. Per-stub median 20.77 (pole-balance-markov-vac) to $122.05 (pipe-6-bit-parity, which hit a tricky LSTM training issue and needed extra turns).
74 distinct sessions participated: the lead plus 73 subagent dispatches (58 builders, 15 auditors). Each subagent gets its own JSONL file in the same project directory. The lead’s file only records the dispatch call and the subagent’s final return, not the subagent’s internal turns. To count what the build cost, you have to walk the directory. The script that does it is at analysis/scripts/ and the data it produces is at analysis/data/. Per-pool, per-wave breakdown at cost rollup.
What broke and how it was fixed
Six things broke. Each has a timestamp and a fix.
- Branch-per-stub got pushed to origin (wave 1, 2026-05-07 01). The per-stub policy would have pushed 58 branches to the remote. PR #2 closed, reissued as PR #5 on
wave/0-sanity. From wave 2 onward, all stub branches stayed LOCAL ONLY. - Workers committed locally and went silent (waves 3, 10, 11). The lead nudged each with an explicit
Request summary messageSendMessage. Worker prompt template updated: “DO NOT GO SILENT: send a summary explicitly.” The recovery state in the worker lifecycle:
- Orphan
problem.pystub files (waves 6 and 7). Workers wrote new files but didn’tgit rmthe placeholder. Caught by the audit subagent. Cleanup commits added on top of each wave merge. - Wrong git author identity. One wave-3 commit authored as
agent-pomdp-flag-maze-builder <agent@anthropic.com>. The per-worktree git config was overridden by Claude Code’s session-default identity. Resolved post-merge with agit filter-branchrewrite: 74 commits →Yad Konrad. Force-pushed main. - GitHub Pages deploy failed first try. One API call (
gh api -X POST repos/.../pages -F build_type='workflow') and a workflow rerun fixed it. - First BUILD_NOTES had fabricated counts, written from memory. PR #20 rewrote it from the actual JSONL session log.
Every fix is documented at what worked, what didn’t. The 8-step recipe for running it yourself is at how to reproduce.
Yaroslav’s three asks, delivered
Going back to the kickoff message:
- BUILD_NOTES.md: full session forensics, every prompt, every wave, every error and recovery. On the repo.
- Experiment visualizations: every stub ships an animated GIF showing the learning dynamics, plus weight and curve visualizations in
viz/. The VISUAL_TOUR.md walks through all 58 in order. - Workbook stats: RESULTS.md has the full per-stub catalog: paper, reproduces yes/partial/no, run wallclock, headline metric, implementation budget. Sortable, comparable, machine-readable.
After the post-merge polish round, Yaroslav had one more piece of feedback: “could you add a link to the github on https://cybertronai.github.io/schmidhuber-problems/index.html, maybe instead of ‘Site:’, have ‘Github:’.” Fixed in the next commit. The PR-comment cycle works the same way for small wording changes as for full implementation reviews.
Then the next ask landed:
“@yad3k maybe this is too ambitious for agents today, but an ideal agent v3 task would be: Follow example of https://github.com/cybertronai/sutro-problems/tree/main/matmul to create a read-distance histogram for a feasible subset of hinton-problems and schmidhuber-problems”
That is the v3 path. Read-distance histograms are the data-movement metric, joules per inference decomposed by where each byte was loaded from in the cache hierarchy. With the instrumented baselines in hand from v2, v3 returns to the question Yaroslav started the project with: which of these old algorithms beat backprop on data movement.
The program-synthesis rhyme
The build is structurally a program-synthesis pipeline applied to itself. Same loop, just at the scale of paper-stubs instead of single functions, mapped to concrete artifacts:
| Program-synthesis primitive | What it was in this build |
|---|---|
| Specification | SPEC issue #1. 8-section README template, 10-item acceptance checklist, algorithmic-faithfulness rule, pure-numpy constraint |
| Exemplar | A reference stub from the previously-built hinton-problems repo, cited in every worker prompt |
| Candidate generation | 58 parallel Agent dispatches, each producing a candidate implementation |
| Verifier | The per-wave Explore audit subagent (read-only) |
| Acceptance gate | Audit verdict → wave PR opened → batch-merge at the end (the human approval is the final acceptance step) |
| Autonomous handoff | Yad’s 2026-05-07 02 UTC prompt: “I need you to not rely on me anymore” — the audit-then-dispatch loop ran eight waves without further direction after that |
From the human side the same loop reads as a trust ladder, where each rung is earned by the previous one working.
- Specification. Write it once, reference it everywhere. Eliminates instruction drift.
- Exemplar. Point to a finished sibling stub. Eliminates “what should it look like” guesswork.
- Implementation. N parallel workers attempt the spec; each commits to its own LOCAL-ONLY branch. No coordination overhead.
- Self-review. One
Exploreagent reads all wave-N stubs and posts a verdict. The verifier is a separate role from the implementer. - Human handoff. Once the audit-verdict-acceptance loop works for one wave, the next eight waves don’t need a human. You return for the batch merge.
Each of the six errors above corresponds to a layer where one of these rungs wasn’t holding: the wave-1 branch-spam (no rung-2 exemplar of the right workflow), the silent-after-commit workers (rung-3 spec wasn’t explicit enough), the orphan stub files (rung-4 audit catch), the wrong git author (rung-5 missed at handoff).
And the catalog itself contains literal program-synthesis algorithms. levin-count-inputs and levin-add-positions implement Levin universal search (deterministic program enumeration by Kolmogorov complexity). oops-towers-of-hanoi is Schmidhuber’s Optimal Ordered Problem Solver. pipe-symbolic-regression and pipe-6-bit-parity are Probabilistic Incremental Program Evolution.
Chimera has the deeper synthesis treatment: DSL is tools + environment, synthesizer is agent + loop, verifier is test suite + harness, oracle is spec. The build-internals program-synthesis page develops the framing in detail.
What two runs surfaced that one didn’t
Four things showed up only because the methodology ran twice and the second run was instrumented from the JSONLs instead of from memory.
The SPEC has a stable core and a domain-specific tail. The eight required README sections, the acceptance checklist, and the reproducibility rule were identical between Hinton and Schmidhuber. The algorithmic-faithfulness rule, the RL-stub rule, and the architecture-deviation rule were Schmidhuber addenda. The next domain will need its own tail, and the corrections from each run belong in the next SPEC rather than in the chat history of the previous one.
The branch-spam pattern from Hinton’s run had to be re-corrected in Schmidhuber’s wave 1. The lesson hadn’t transferred because it lived in my memory and the prior chat rather than in any artifact the new orchestrator could read.
The cache_write_1h share, 4% of tokens and 36% of the bill, was invisible without summing the cache pools by sub-type across 74 sessions.
The human ratio came in at 8-out-of-40, measured. Before running it twice I’d have guessed higher.
Community uptake started during the writeup. Armins on Telegram, 2026-05-09: “excited about schmidhuber as inspiration agents to try. I found telling claude code adapt solution from repo X to this problem works much better.” Mark Saroufim referenced the build in his MLSys keynote on 2026-05-21. Cosmin Negruseri’s “learnings, what worked well, what didn’t, how to repro” is the question the Build internals book is structured to answer.
Where this leaves me
Hinton was 53 stubs in 49 hours. Schmidhuber was 58 stubs in 41 hours. The SPEC shape, the agent-teams primitive, and the wave structure carried over from one run to the next without modification, which was the methodological test under the Hinton post.
The build sits one rung up from a chain of earlier posts. Chimera decomposed coding agents into primitives. SutroYaro gave them a research protocol. hinton-problems was the first end-to-end run against someone else’s published agenda. schmidhuber-problems repeats that run.
Next is v3: read-distance histograms on the catalogs, backprop measured against its alternatives in joules per inference. The energy question that drove the Sutro project gets a head-to-head comparison across 53 + 58 baseline implementations.
Links
- schmidhuber-problems: 58 stubs, 1989–2025
- Build internals book: structured drill-down of the session
- FAQ: the five questions everyone asks
- How to reproduce: the 8-step recipe
- Orchestration map: the loop visualized
- Worker prompt anatomy: the per-worker template, annotated
- Human in the loop: local-minima escape, with the data
- Cost rollup: per-pool, per-wave breakdown
- Per-wave details: drill into a specific wave
- SPEC issue #1
- Sutro: the parent project on energy-efficient learning
- hinton-problems: the precedent run
- Yaroslav Bulatov: Google Scholar · X